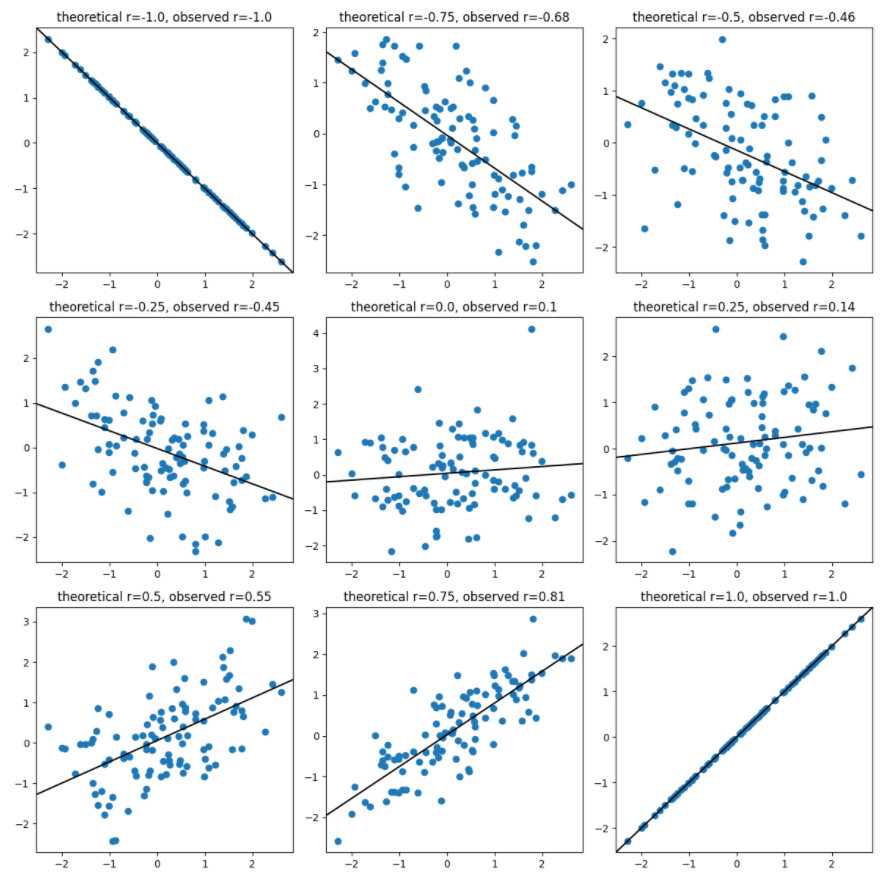
1. Correlation correlation¶
If $X$ and $Z$ are independent, random Normal with mean 0 and standard deviation 1, and $$\begin{aligned} Y = rX + \sqrt{1 - r^2} Z \end{aligned}$$ then $$ \text{cor}[X, Y] = r . $$
(a) Show that this is true, using math.
(b) For each of 16 values of $r$ evenly spaced between -1 and 1,
simulate 100 draws from a bivariate distribution with correlation $r$.
(You should get, for each $r$, 100 pairs $(x_i, y_i)$.)
Use these to make a plot like the following (but with four rows and columns),
with one scatter plot for each simulation, having the minimum-MSE line superimposed,
and both the theoretical and observed correlation in the title.