Spatial smoothing
2026-02-25
Spatial point data: Biketown

Albert in a bike (catmapper:Wikimedia)

biketown bikes (Steve Morgan: Wikimedia)
how biketown works: screenshot
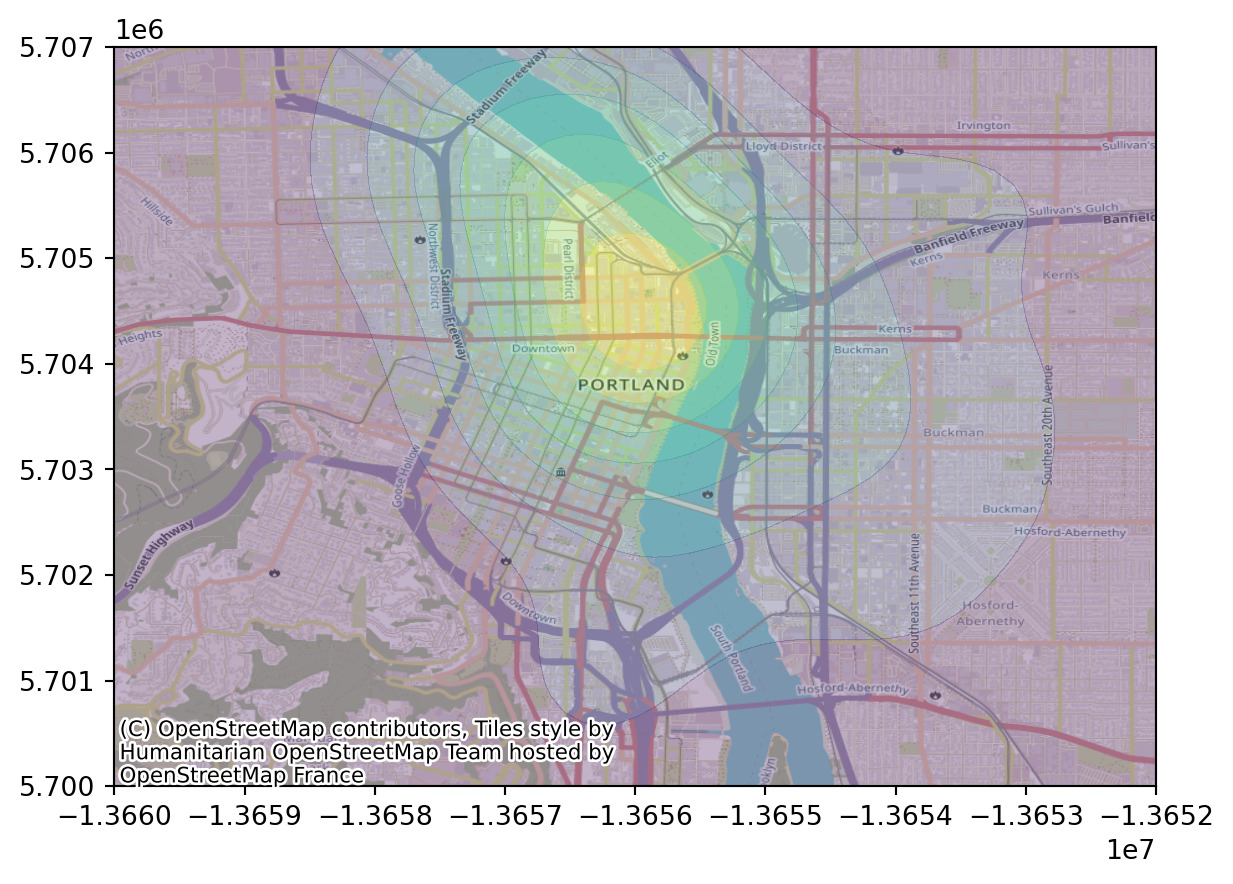
Smoothed map of starting locations
First, we’ll bin things into a 2D grid:
sigma = 500 # meters
delta = 100 # meters
xy = np.array([x.coords[0] for x in gdf['start_points']])
extent = [np.min(xy[:,1]), np.max(xy[:,1]), np.min(xy[:,0]), np.max(xy[:,0])]
xx = np.linspace(extent[2], extent[3], int(abs(extent[3]-extent[2])/delta))
yy = np.linspace(extent[0], extent[1], int(abs(extent[1]-extent[0])/delta))
heatmap, xedges, yedges = np.histogram2d(xy[:,0], xy[:,1], bins=[xx, yy])
plt.imshow(heatmap)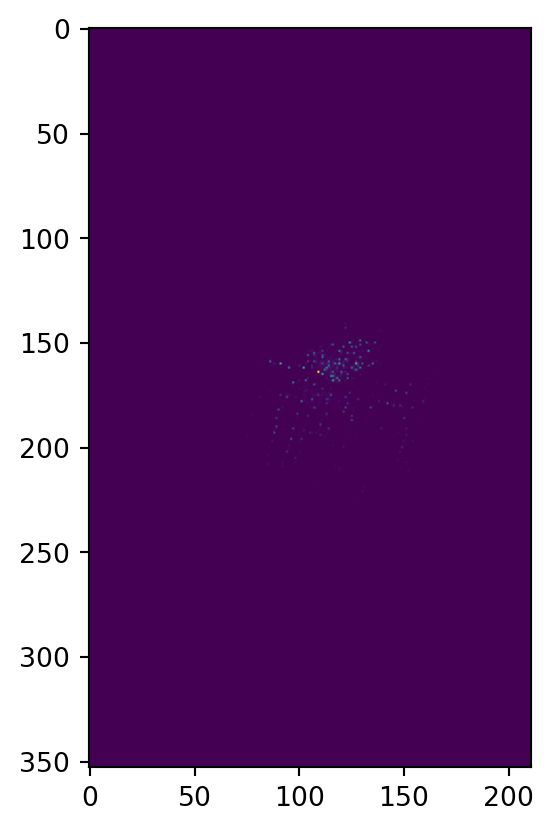
Then, we smooth it: (question: how’s this relate to how we did KDE above?)
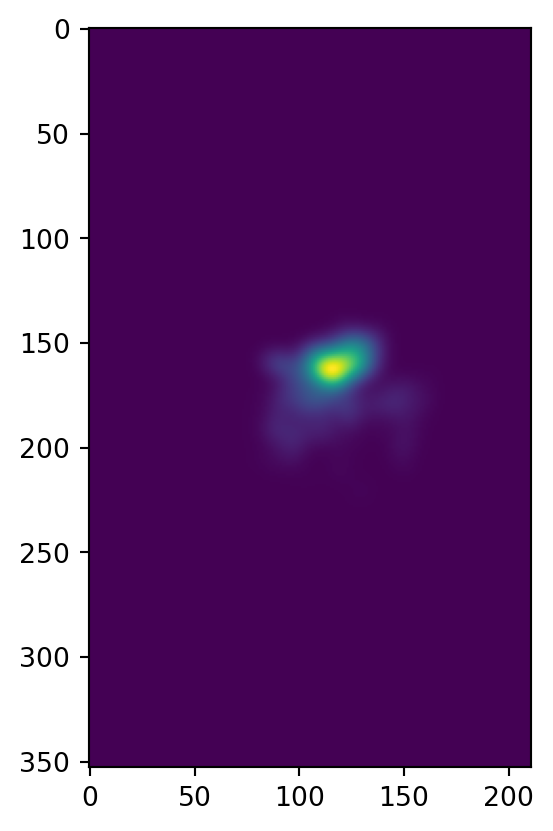
Now, we can superimpose on the OSM map:
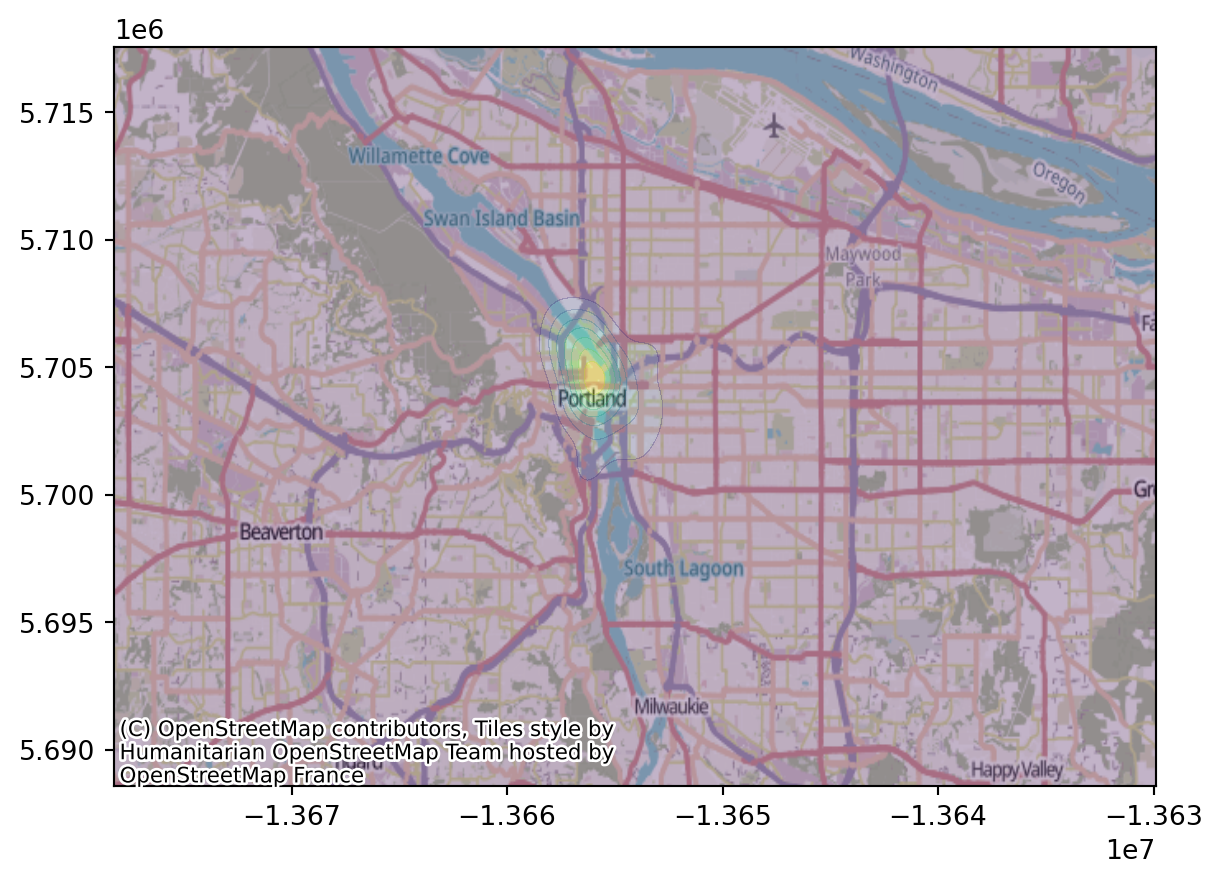
Let’s zoom in: